
観察すべきセグメント。
データエスノグラフィは、一人ひとりの行動データをミクロ視点で観察し、時系列に追うことで、ユーザーの意思決定プロセスの理解や発見を行う手法です。とはいえすべてのユーザーの行動を観察するわけには行きません。そこで、似たユーザーをセグメント(Segment)に分類し、観察すべきセグメントを選定する必要があります。
では、観察すべきセグメントとはいったい誰でしょうか。ここで再び分析目的に立ち戻ります。今回の分析目的は「優良化する会員の行動特性を、購買履歴データから把握する」でした。
優良化の要因となる行動特性を把握するには、優良化している会員と優良化していない会員との間に存在する違いを比較観察すればよいことになります。すなわち因果推論(Causal Inference)1)いまさら聞けない因果推論でいう疑似実験(Quasi Experiment)を行うわけです。
とはいえ、優良かどうかのみでは範囲が広すぎるため、もう少し絞り込みたいところですが、それには結果との相関が強いサブセグメントが有効です。例えば、優良化と高齢者の相関が強ければ、高齢者同士で比較すれば違いを発見しやすくなるはずです。これは疑似実験におけるマッチング法と同じ考え方です。
まとめると、以下の二つの軸で分類していけばよいことになります。
- 優良会員と非優良会員のセグメント
- 優良化との相関が強いサブセグメント
まず優良会員と非優良会員の分類が必要ですが、詳細はさておき、以下のように分類します。
| 会員ランク | 条件 | |
| 1 | 優良 | 購買頻度が30日以上 かつ累積購買金額が10万円以上 |
| 2 | F3 | 購買頻度が3日以上 かつ優良会員の条件に満たない |
| 3 | F2 | 購買頻度が2日 |
| 4 | F1 | 購買頻度が1日 |
結果との相関が強いサブセグメント。
続いて、優良化との相関が強いサブセグメントを探ります。これには大きく、検証的アプローチと発見的アプローチの二つがあります。
検証的アプローチ(Verifying Approach)は、二つの事象間の相関が仮説として想定されるものについて事実を検証していくアプローチで、質的変数であればクロス集計(Cross Tabulation)、量的変数であれば散布図(Scatter Plot)などの手法を用いて分析します。今回の場合でいうと、特定の性別や年代、あるいは購買商品カテゴリなどの変数と優良化との間に相関があるのではないかという仮説をたてて検証していきます。
一方で、人の行動を決定づける要因は無数にあるため、優良化につながる思わぬ要因が潜んでいる可能性がありますが、検証的アプローチでそれを見つけることはできません。そこで多くの変数をもつデータから、二つの事象間の相関を機械的に取り出すアプローチが有効となります。それを、発見的アプローチ(Discovering Approach)といい、主にアソシエーション分析(Association Analysis)2)アソシエーション分析入門やクラスタリング(Clustering)などの手法があります。
とはいえ今回のように、分析対象データの変数が少ない場合は検証的アプローチで十分です。ではBigQueryとTableauで実際に検証していきます。なお、それぞれの使い方については「BigQueryではじめるSQL」「TableauではじめるBI」を参照してください。
検証的アプローチで相関分析。
まずは分析用のテーブルを作成します。検証したいのは、特定の性別・年代・購買商品カテゴリと会員ランクの間に相関があるかどうかですが、それには会員IDごとに性別・年代・購買商品カテゴリ・会員ランクの変数をもつテーブルを作成する必要があります。BigQueryのクエリエディタに以下のSQL文を入力し、青い[実行]ボタンをクリックしてみましょう。
なお、処理の効率化のために10%のサンプリングをしていますが[※1]、これは会員IDを10で割った剰余が0の場合に限定するという意味です。また、欠損を除外するために性別がNULLでない会員に限定し[※2]、年齢の異常値を除外するために10歳以上90歳未満の会員に限定しています[※3]。さらに、時系列データの開始と終了の問題を解決するために、初回購買日が2006年1月以後かつ最終購買日が2012年12月以前の会員に限定しています[※4]。
すると、以下のスキーマのテーブルが出力結果で表示されるので、それをデータセット「DE」に「sum_members」という名前で保存します。
| フィールド名 | 概要 | タイプ |
| member_id | 会員ID | 整数 |
| gender | 性別 | 文字列 |
| age | 年齢 | 整数 |
| category | 購買商品カテゴリ ※複数ある場合はランダム | 文字列 |
| first_date | 初回購買日時 | 日時 |
| last_date | 最終購買日時 | 日時 |
| frequency | 購買頻度(日数) | 整数 |
| monetary | 累積購買金額 | 整数 |
| rank | 会員ランク | 文字列 |
続いて、テーブル「sum_members」をTableauに取り込んで分析します。Tableau Desktopであれば、スタート画面の[接続]にあるメニュー[Google BigQuery]から選択するだけでシームレスに連携できます。Tableau Publicであれば、GCS(Google Cloud Storage)経由でCSVファイルとしてエクスポートしてから取り込みます。
あとは、性別・年齢・購買商品カテゴリと会員ランクの関係を可視化して分析するだけです。
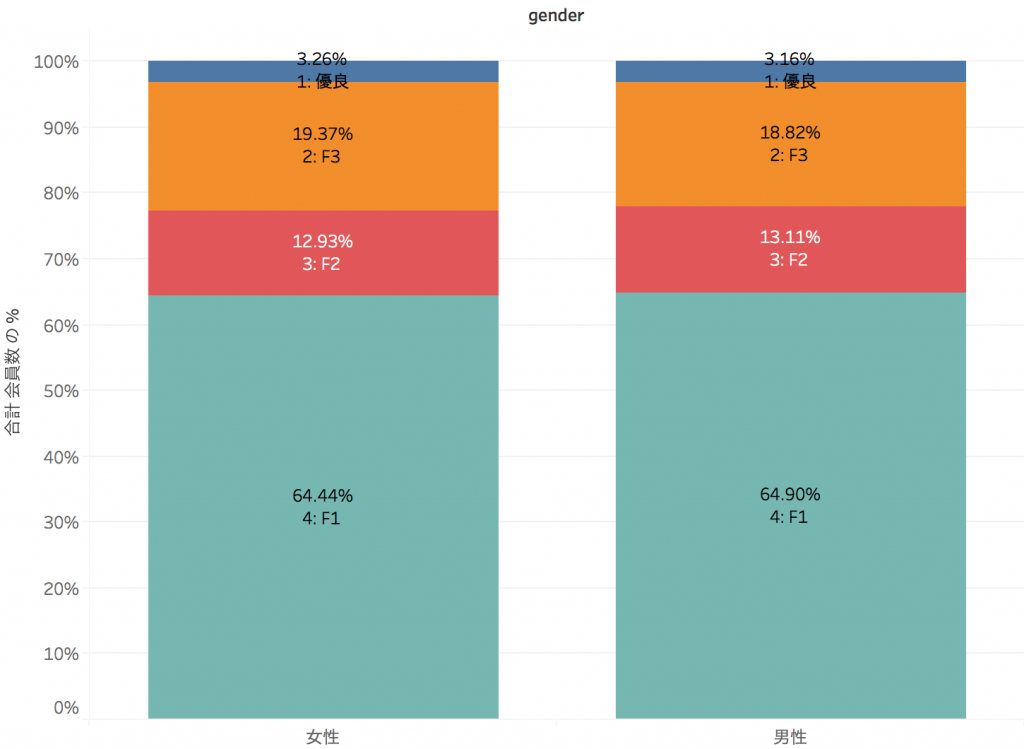
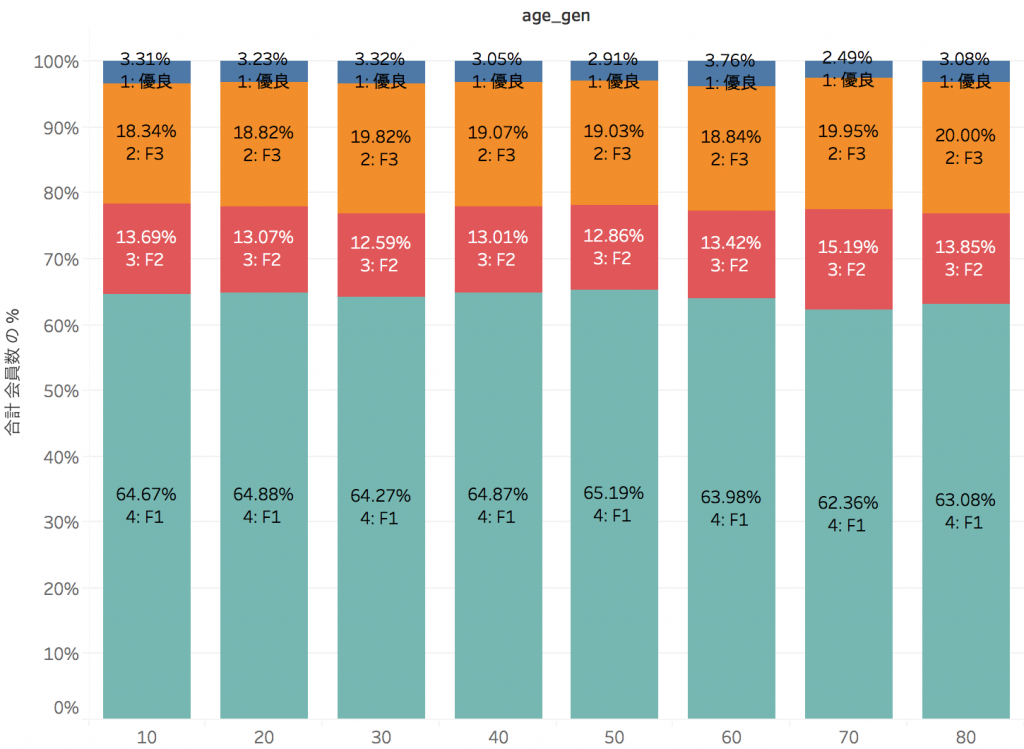
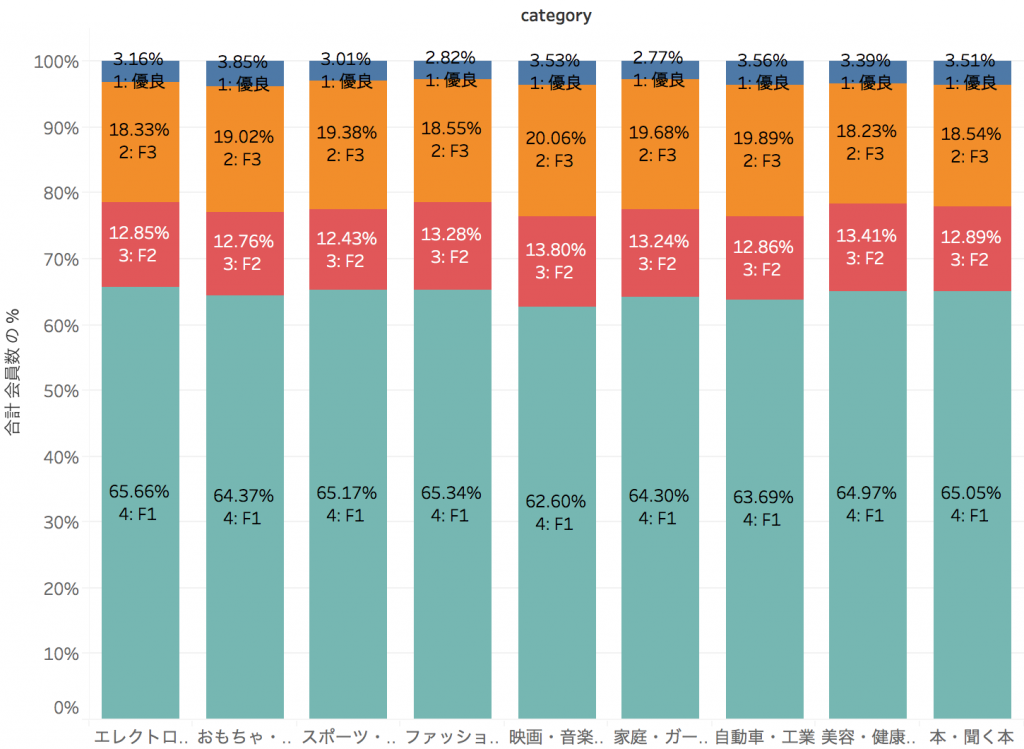
これらは、性別・年代別・購買商品カテゴリ別での会員ランクの構成比率ですが、どの切り口でもほぼ同じで、性別・年齢・購買商品カテゴリは、会員の優良化に対して何の影響も及ぼしていないことがわかります。どうやら今回の分析対象データからは、優良化との相関が強いサブセグメントを特定することは難しそうです。
ということで「データエスノグラフィ入門」最終回である次回は、サブセグメントでの絞り込みは諦めて、会員ランクごとに行動データを観察していくことにします。


須川 敦史
UX&データスペシャリスト
クロスハック 代表 / uxmeetsdata.com 編集長
脚注
| 1. | ↑ | いまさら聞けない因果推論 |
| 2. | ↑ | アソシエーション分析入門 |
