
新しい商品カテゴリの提案。
それでは、Cloud Datalabを利用した、Pythonによるアソシエーション分析のプログラミングを実践していきます。
今回は「データエスノグラフィ入門」と連動し、とある総合ECサイトの商品の併売傾向を深堀分析するという設定です。まず分析の背景と目的をおさらいします。
あなたは、とある総合ECサイトの責任者です。ECサイトでは、F2転換率が重要であると言われています。この”F”は購買頻度(Frequency)のことで、F2転換率とは初回購買から二回目購買への転換率(Conversion Rate)を意味します。一般的に、新規会員の獲得よりも、既存会員のリピート購買促進のほうがコスト効率が高いため、F2転換率は重要な指標となります。とはいえF2転換した会員が、その後も継続的に購買してくれる、いわゆる優良会員になるとは限りません。
そこで今回の分析目的を「優良化する会員の行動特性を、購買履歴データから把握する」とします。なおそこには、まだ優良化していな会員を意図的に優良化するためのヒントがあることは言うまでもありません。
分析対象データは、とある総合ECサイトの会員の購買履歴データで、概要は以下のとおりです。
- 種類:総合ECサイトの会員の購買履歴
- 期間:2005年1月〜2013年12月(9年間)
- 会員数:639,777人
- 購買数:7,599,650件(平均11.9件/人)
データソースは以下の3つを使用します。なお、こちらはすでにBigQueryに投入済みとします。
| データソース | 変数 | ダウンロード |
| 会員マスタ mst_members |
会員ID, 年齢, 性別, 居住地など | [↓]105MB |
| 商品マスタ mst_products |
商品ID, 商品カテゴリなど | [↓]53MB |
| 購買履歴 trx_orders |
会員ID, 商品ID, 注文日, 価格 | [↓]698MB |
すべてのユーザーの行動の観察はできないため、似たユーザーをセグメント(Segment)に分類し、観察すべきセグメントを選定します。優良化の要因となる行動特性を把握するには、優良化している会員と優良化していない会員との間に存在する違いを比較観察すればよいので、観察すべきセグメントとはその二つになりますが、もう少し絞り込むために優良化との相関が強いサブセグメントを見つけます。例えば、優良化と高齢者の相関が強ければ、高齢者同士で比較すれば違いを発見しやすくなるということです。
優良化との相関が強いサブセグメントを見つけるには、まず二つの事象間の相関が仮説として想定されるものについて事実を検証していく検証的アプローチ(Verifying Approach)による分析を行います。今回の場合でいうと、特定の性別や年代、あるいは購買商品カテゴリなどの変数と優良化との間に相関があるという仮説を検証していきます。しかしながら、それらに相関がないことがわかりました。(※「データエスノグラフィ入門 #03」を参照)一方で、行動データ観察を進める中で、購買商品カテゴリ数と優良化との間に相関があることがわかりました。(※「データエスノグラフィ入門 #04」を参照)とりわけ購買商品カテゴリ数が8以上で優良会員の比率が大きく増えるため、そのサブセグメントに絞って行動データ観察をすると、優良化の要因となる行動特性を発見しやすくなると考えられます。
さらに、購買商品カテゴリ数と優良化の相関性は、新たな商品カテゴリを提案することが優良化につながる可能性を示唆しています。ただし、闇雲に提案するよりも、購買経験済みの商品カテゴリとの併売傾向が強い商品カテゴリを提案するほうが効果が高いと考えられます。そこでアソシエーション分析によりそれを明らかにします。
分析用のデータと環境を準備。
まずはBigQueryで分析用のテーブルを作成します。アソシエーション分析では会員IDごとに購買商品カテゴリの変数を持つテーブルが必要になりますが、購買商品カテゴリの数は会員ごとに異なるため、ARRAY_AGGという集計関数を用いて配列型で集計します。BigQueryのクエリエディタに以下のSQL文を入力し、青い[実行]ボタンをクリックしてみましょう。また、このクエリ結果をデータセット「DE」に「sum_members_aso」という名前で保存します。なお併売傾向を捉えるには、購買商品カテゴリ数が複数である必要があるため、2以上の会員に限定しています[※1]。
続けて、Cloud Datalabでアソシエーションルールを作成するための実行環境を準備します。とはいえCloud Datalabには、GCP(Google Cloud Platform)との連携や、メジャーなデータ分析・機械学習系の拡張モジュールがあらかじめインストールされているため、多くはインポートするだけです。
まずはデータ分析用の拡張モジュールである「pandas」をインポートします。これはBigQueryから取り込んだ分析用テーブルをデータブレームで操作するためですが、同時にBigQueryとの直接クエリによる連携も可能となります。
また、アソシエーションルールの抽出ロジック自体は単純なため自作も可能ですが、大量データからの抽出には膨大な計算処理が必要となるため、高速化するアプリオリ(Apriori)というアルゴリズムを使用します。アプリオリを実装した拡張モジュールはいくつかありますが、いずれもCloud Datalabにはインストールされていないため、追加インストールが必要となります。今回は「mlxtend」という拡張モジュールを用います。インストールはpipコマンドで実施します。
ここまでの拡張モジュールの準備は、以下のコードで行うことが可能です。入力エリアに記述し、実行してみてください。
拡張モジュールの準備が完了したら、BigQueryで作成した分析用テーブルを取り込みます。それには「read_gbq」関数を使い、引数にBigQueryのクエリを実行するSQL文とGCPのプロジェクトIDを指定します。以下のコードを入力エリアに記述し、実行してみてください。
これでアソシエーションルールを抽出するための分析用のデータが整いました。
アソシエーションルールを作成。
では、アプリオリ・アルゴリズムの拡張モジュールであるmlxtendを用いて、アソシエーションルールの作成を行います。プログラム内容の詳細な説明はここでは割愛しますが、以下のようなコードで実現できます。入力エリアに記述し、実行してみてください。
なお「アソシエーション分析入門 #01」でも触れたとおり、分析の効率化のため、支持度とリフトについては、閾値を下回る組み合わせを事前に分析対象から除外します。ここでは支持度の閾値を0.1、リフトの閾値を1とします。プログラムでは「apriori()」関数の引数「min_support」が支持度の閾値の指定となるため「0.1」を代入します。また「association_rules()」関数の引数「metric」が閾値設定対象の指標の指定となるため「”lift”」を、同じく引数「min_threshold」がその閾値の指定となるため「1」を代入します。
最後の行の「df_table」というデータフレーム型の変数に、作成したアソシエーションルールが格納されています。入力エリアに「df_table」と記述して実行してみましょう。すると以下のような表が出力されます。
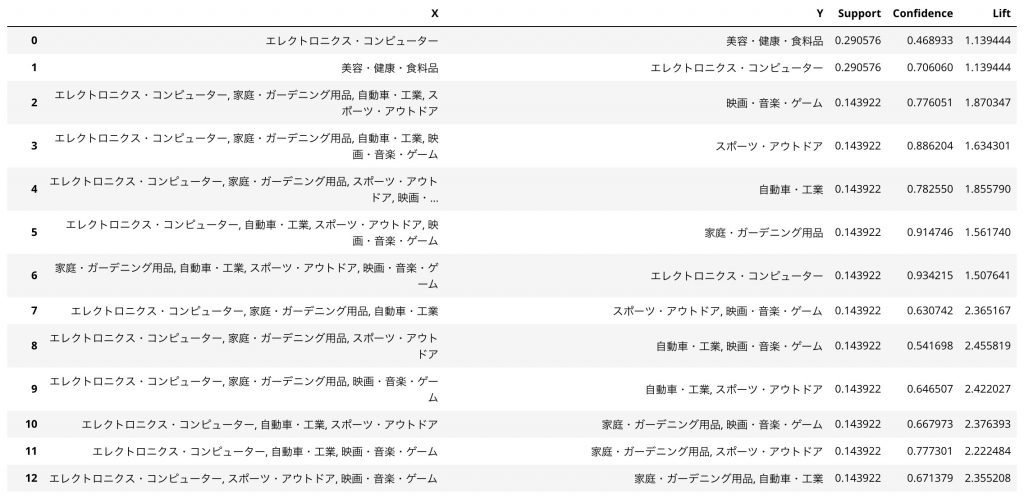
上表の列「X」「Y」は購買した商品カテゴリ、「Confidence」は信頼度、「Support」は支持度、「Lift」はリフトとなります。例えば、基本指標である商品カテゴリ「美容・健康・食料品」を購買した顧客が「エレクトロニクス・コンピューター」も購買する確率(信頼度)は0.70…で、補足指標である支持度は0.29…、リフトは1.13…となります。この状態でもアソシエーションルールの一部は見てとれますが、より分析をしやすくするためにTableauで可視化することにします。
次回は、作成したアソシエーションルールをBigQueryに書き出し、Tableauで可視化しながらアソシエーション分析を行います。
※参考までに、アソシエーションルールの作成をCloud DatalabではなくColabで行う場合のプログラムを以下に掲載しておきます。Cloud Datalabを利用できない方はこちらでお試しください。


須川 敦史
UX&データスペシャリスト
クロスハック 代表 / uxmeetsdata.com 編集長
