
アソシエーションルールを可視化。
Cloud DatalabにてCSPADEアルゴリズムの拡張モジュールであるpycspadeを用いて作成したアソシエーションルールを、BigQueryに書き出し、Tableauで可視化しながら系列パターンの分析を行います。
まずは前回の続きで、以下のコードを入力エリアに記述し、実行してみましょう。なお「to_gbq」関数の引数には、アソシエーションルールを格納したデータフレーム、書き込み先のテーブル名、GCPのプロジェクトIDを指定します。
なお、BigQueryへの書き出しがうまく行かない場合は、以下のコードでCSVファイルに書き出し、GCS(Google Cloud Storage)経由でBigQueryに取り込みます。
以下のように、BigQueryのデータセット「XM」の中に「sum_rules_spm」というテーブルが作成されていることを確認します。
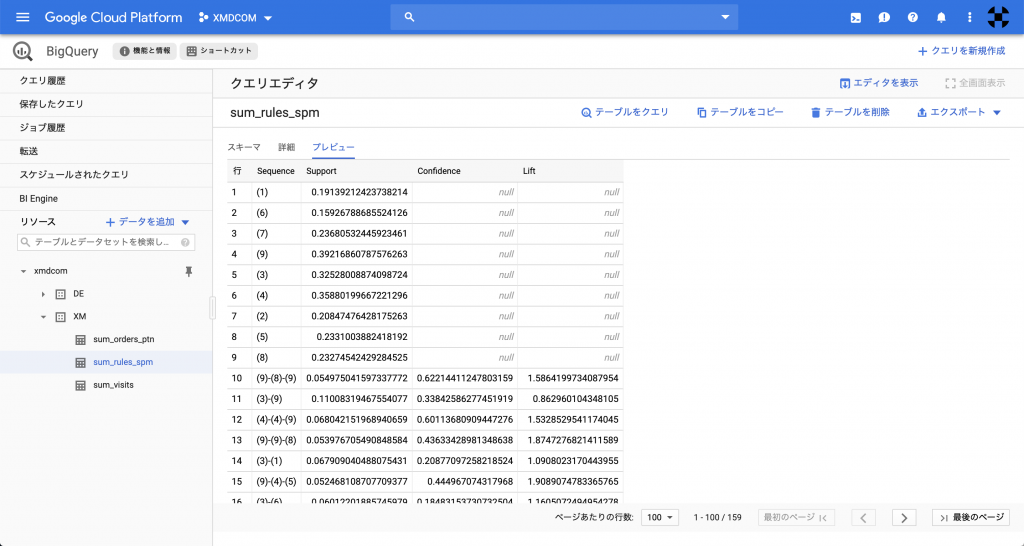
続いて、テーブル「sum_rules_spm」をTableauに取り込んで分析します。Tableau Desktopであれば、スタート画面の[接続]にあるメニュー[Google BigQuery]から選択するだけでシームレスに連携できます。Tableau Publicであれば、GCS(Google Cloud Storage)経由でCSVファイルとしてエクスポートしてから取り込みます。
Tableauへの取り込みが完了したら、以下の手順でクロス集計表を作成し、アソシエーションルールを可視化します。
- フィールドの「Sequence」を[行]、「Confidence」を[列]シェルフにそれぞれドラッグ&ドロップ。
- フィールドの「Confidence」を[マーク]カードの[色]にドラッグ&ドロップ。
- 右上に表示される「合計(Confidence)」カードの右上の▼のメニューで[色の編集…]を選択。
- [色の編集]モーダルで[ステップド カラー]チェックをオン、[詳細]ボタン押下で表示される[中央]チェックをオンに設定。
- フィールドの「Confidence」「Support」「Lift」を順に[マーク]カードの[テキスト]にドラッグ&ドロップ。
- フィールドの「Confidence」「Support」「Lift」のそれぞれについて、ピルの右端の▼のメニューで[フィルタを表示]を選択。
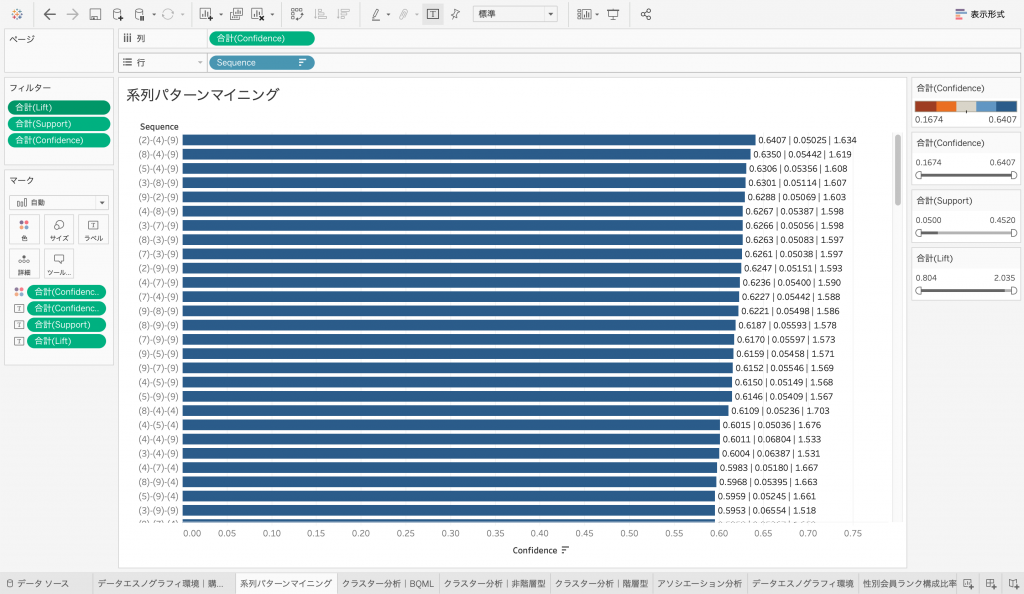
系列パターンを分析する。
では、この表をもとに系列パターンを分析してみましょう。「アソシエーション分析入門 #01」でも触れたとおり、アソシエーションルールの指標の中でも、信頼度(Confidence)は、商品Xを購買した顧客が商品Yも購買する確率のことで、事象間の相関性を分析する基本指標となります。
一方で、前回に述べたとおり、リフトは1を下回ると負の影響力を意味するため、予め除外するのが通例ですが、pycspadeでは閾値設定ができないため1未満の系列パターンも含まれてしまっています。そこでリフトを1以上としてフィルタをかけます。右側の「合計(Lift)」フィルタの左側の最小値設定を1.0に変更すると、以下のように表示が切り替わります。ただし、初期ビューで見えている系列パターンはすべてリフトが1以上であるため、初期ビューの表示自体は変わりません。
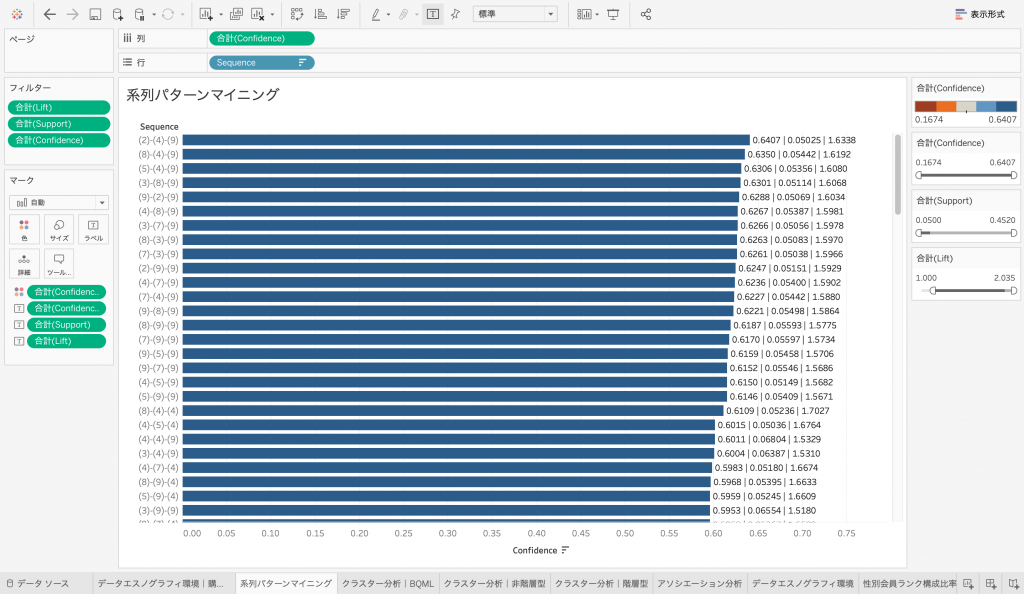
信頼度の降順に見ていくと、まず最後に商品カテゴリIDが「9」すなわち「エレクトロニクス・コンピューター」を購買しているパターンが多いことが一目瞭然となります。さらに、その前に「4」すなわち「家庭・ガーデニング用品」を購買しているパターンが多いこともわかります。
これらの原因はわかりませんが、とにかくこのパターンで購買商品カテゴリが変化している購買行動パターンが多いという事実が可視化され、把握することが可能となるわけです。
対象ユーザーを抽出して観察。
最後に、獲得した行動パターンに基づいて、観察対象とするユーザーを抽出し、行動を観察します。すなわちデータエスノグラフィ(Data Ethnography)1)データエスノグラフィって?を行うわけです。UXモデリングにより獲得したモデルは、あくまで機械的に抽出された行動パターンに過ぎません。ユーザーの行動の因果関係を把握し、意思決定プロセスを理解するには、やはり一人ひとりの行動データをミクロ視点で観察し、時系列に追う必要があります。UXモデリングはそれを効率化する手法という位置付けです。
とはいえ、抽出したパターンに一対一で紐づく会員のリストを得ることができないため、系列パターンに含まれる商品カテゴリを購買履歴に含む会員を抽出し、その中からサンプリングしつつ観察するというアプローチをとることにします。
指定した商品カテゴリを購買履歴に含む会員を抽出しやすいようにデータを加工します。BigQueryのクエリエディタに以下のSQL文を入力し、青い[実行]ボタンをクリックしてみましょう。また、このクエリ結果をデータセット「XM」に「sum_orders_ptn」という名前で保存します。
続いて、テーブル「sum_orders_ptn」をTableauに取り込んでデータエスノグラフィをします。ワークシート編集画面で「A00_member_id」を[行]、「C01_frequency」「C02_monetary」を[列]、「C00_rank」を[フィルター]と[色]に、それぞれドラッグ&ドロップすると、データエスノグラフィ環境の構築は完了です。
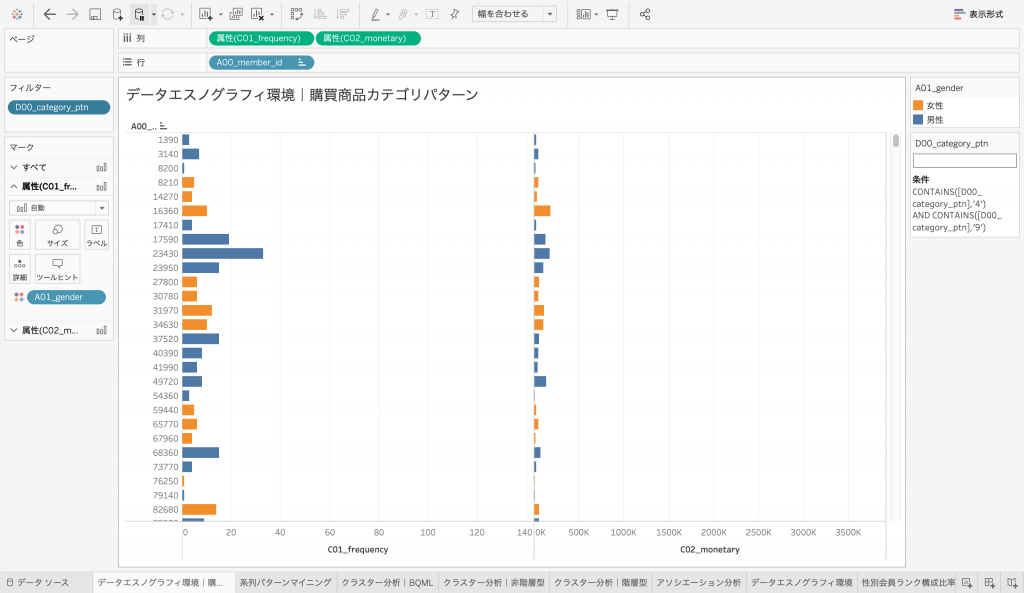
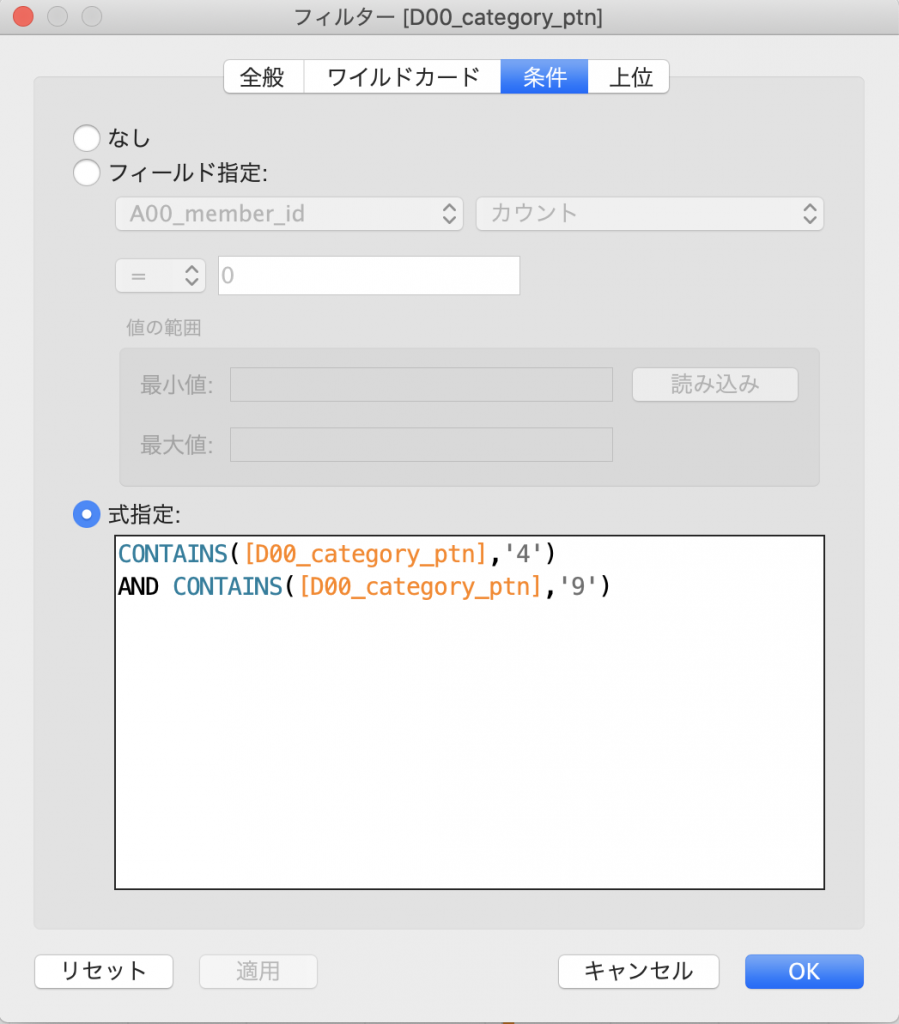
ここで、さきほどの系列パターン分析で注目した、商品カテゴリ「4」と「9」を含む会員IDを抽出して行動データを観察できるようにします。それには「D00_category_ptn」をフィルターに追加し、[フィルターの編集]から[フィルター]モーダルを立ち上げ、[条件]タブの[式設定]にて、以下のフィルター条件を指定します。なおこれは、「D00_category_ptn」カラムに「4」と「9」のどちらも含む会員IDに絞り込むことを意味します。
CONTAINS([D00_category_ptn],'4') AND CONTAINS([D00_category_ptn],'9')
絞り込まれた会員IDから任意に選んで、実際の購買履歴データを見てみましょう。例えば会員ID「16360」の会員の購買履歴はこのようになっています。
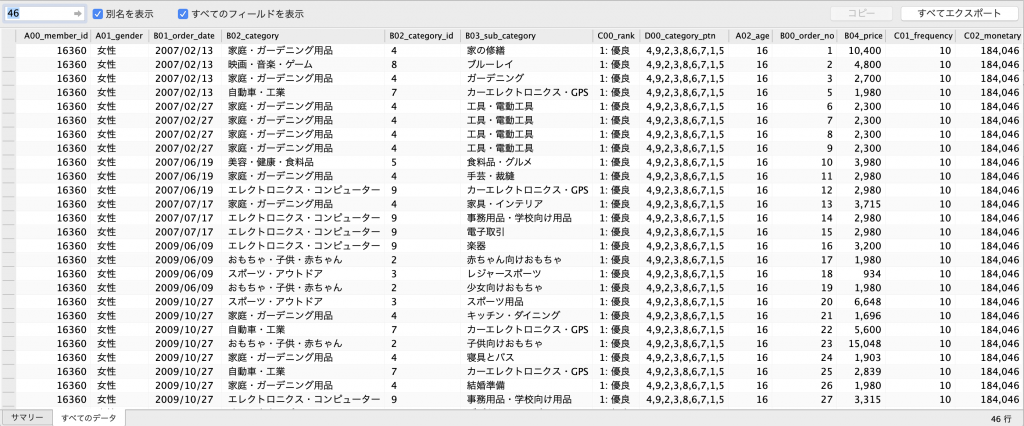
確かに「家庭・ガーデニング用品」関連商品の購入から始まり、次の訪問時に「エレクトロニクス・コンピューター」関連商品の購入をしています。さらにサブカテゴリを見ると、「カー・エレクトロニクス」関連商品が共通項として見られます。またその二年後には「赤ちゃん向けおもちゃ」関連商品を購入しています。このあたりにライフステージの変化のヒントがあるように考えられます。
このようにUXモデリングは、大量のデータから、系列パターンというシンプルなユーザー行動モデルを機械的に抽出し、観察すべきユーザーの絞り込みを効率化する手法であることを理解してもらえたのではないかと思います。


須川 敦史
UX&データスペシャリスト
クロスハック 代表 / uxmeetsdata.com 編集長
脚注
| 1. | ↑ | データエスノグラフィって? |
