
モデリング用のデータを準備。
まずはBigQueryでモデリング用のテーブルを作成します。なお、ここでは系列パターンマイニング(Sequential Pattern Mining:SPM)の代表的なアルゴリズムであるCSPADEを使用しますが、それには会員IDと購買単位ごとの購買商品カテゴリIDの配列をもつテーブルが必要になります。購買単位とは一回の購買を意味し、通常は買い物かごを指しますが、今回のデータには買い物かごに相当するものが存在しないため、同じ日付の購買を一回の購買とみなすことにします。
また、今回の商品マスタには商品カテゴリIDに相当するものが存在しないため、以下のようにIDを定義して付与します。なお、IDは本来は整数で扱うべきですが、後ほど使用するPythonのデータ分析用拡張モジュールである「pandas」においてBigQueryデータの読み込みがうまく処理されないため、文字列で定義します。
| 商品カテゴリID | 商品カテゴリ名 |
| 1 | ファッション・ジュエリー |
| 2 | おもちゃ・子供・赤ちゃん |
| 3 | スポーツ・アウトドア |
| 4 | 家庭・ガーデニング用品 |
| 5 | 美容・健康・食料品 |
| 6 | 本・聞く本 |
| 7 | 自動車・工業 |
| 8 | 映画・音楽・ゲーム |
| 9 | エレクトロニクス・コンピューター |
BigQueryのクエリエディタに以下のSQL文を入力し、青い[実行]ボタンをクリックしてみましょう。
なお、処理の効率化のために10%のサンプリングをしていますが[※1]、これは会員IDを10で割った剰余が0の場合に限定するという意味です。また、欠損を除外するために性別がNULLでない会員に限定し[※2]、年齢の異常値を除外するために10歳以上90歳未満の会員に限定しています[※3]。さらに、時系列データの開始と終了の問題を解決するために、初回購買日が2006年1月以後かつ最終購買日が2012年12月以前の会員に限定しています[※4]。
すると、以下のスキーマのテーブルが出力結果で表示されるので、それをデータセット「XM」に「sum_visits」という名前で保存します。
| フィールド名 | 概要 | タイプ |
| member_id | 会員ID | 整数 |
| visit_id | 訪問ID | 整数 |
| category_id | 商品カテゴリID | 文字列の配列 |
モデリング用の実行環境を準備。
続けて、Cloud DatalabでSPMによるアソシエーションルールを作成するための実行環境を準備します。とはいえCloud Datalabには、GCP(Google Cloud Platform)との連携や、メジャーなデータ分析・機械学習系の拡張モジュールがあらかじめインストールされているため、多くはインポートするだけです。
まずはデータ分析用の拡張モジュールである「pandas」をインポートします。これはBigQueryから取り込んだ分析用テーブルをデータブレームで操作するためですが、同時にBigQueryとの直接クエリによる連携も可能となります。
また、ここではSPMの代表的なアルゴリズムであるCSPADEのPython向け拡張モジュールである「pycspade」を使用しますが、Cloud Datalabにはインストールされていないため、追加インストールを行います。
ここまでの拡張モジュールの準備は、以下のコードで行うことが可能です。入力エリアに記述し、実行してみてください。
拡張モジュールの準備が完了したら、BigQueryで作成した分析用テーブルを取り込みます。それには「read_gbq」関数を使い、引数にBigQueryのクエリを実行するSQL文とGCPのプロジェクトIDを指定します。以下のコードを入力エリアに記述し、実行してみてください。
なお、商品カテゴリIDについては、先述の理由で文字列型で設定していましたが、ここで整数型に変換します。これでSPMによるアソシエーションルールを抽出するためのデータおよび環境が整いました。
アソシエーションルールを作成。
では、CSPADEアルゴリズムの拡張モジュールであるpycspadeを用いて、系列パターンのアソシエーションルールの作成を行います。プログラム内容の詳細な説明はここでは割愛しますが、以下のようなコードで実現できます。入力エリアに記述し、実行してみてください。
なお、アソシエーションルール(Association Rule)の詳細の説明は「アソシエーション分析入門 #01」に譲りますが、簡単に言えば「商品Xを購入した顧客は商品Yも購入している」といった規則性のことで、信頼度・支持度・リフトの三つの指標を使うのが一般的です。
信頼度(Confidence)は、商品Xを購買した顧客が商品Yも購買する確率のことで、併売戦略やレコメンデーションにむけた分析の基本指標となります。
支持度(Support)は、全体の購買の中で商品Xと商品Yのどちらも購買される確率のことで、補足指標となります。仮に、商品Xを購買した顧客が商品Yも購買する確率(信頼度)が80%だったとしても、商品Xと商品Yのいずれも購買した顧客が全体の1%にも満たない場合、統計的な信頼性が低いだけでなく、それをもとに併売戦略を立てたところでビジネス的に意味はありません。そこで補足指標として支持度を用います。
リフト(Lift)は、全体の購買の中で商品Yが購買される確率に対する商品Xを購買した顧客が商品Yも購買する確率(信頼度)の割合のことで、こちらも補足指標となります。仮に、商品Xを購買した顧客が商品Yも購買する確率(信頼度)が80%だったとしても、そもそも商品Yが購買される確率が80%であれば、商品Xの購買が商品Yの購買に与える影響力を説明することはできません。そこで補足指標としてリフトを用います。
ところで、分析作業の効率化のために、リフトが閾値(1が一般的)を下回る組み合わせは、事前に分析対象から除外するのが慣例ですが、pycspadeではリフトの閾値設定ができません。一方で、支持度の閾値設定は可能であるため「0.05」を指定しています。
最後の行の「df_table」というデータフレーム型の変数に、作成したアソシエーションルールが格納されています。入力エリアに「df_table」と記述して実行してみましょう。すると以下のような表が出力されます。
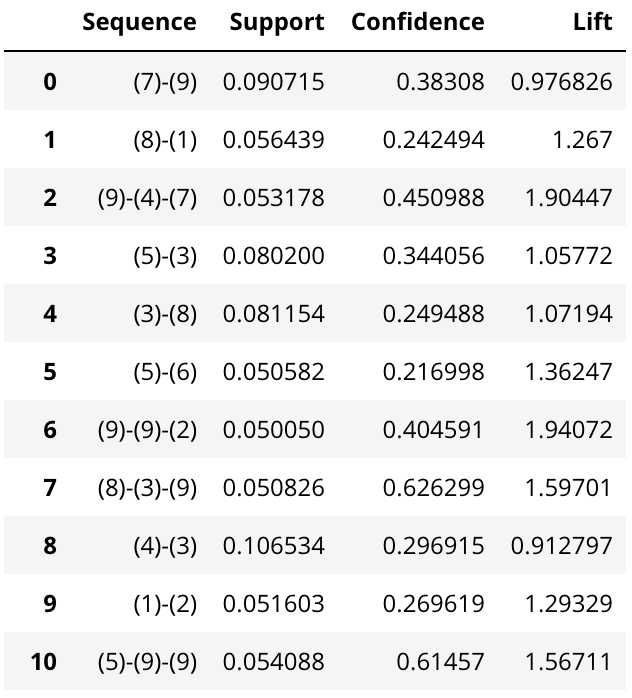
上表の列「Sequence」は系列パターンすなわち購買商品カテゴリの時系列パターン、「Confidence」は信頼度、「Support」は支持度、「Lift」はリフトとなります。例えば、Sequenceが「(7)-(9)」とは、「自動車・工業」関連商品を購入後に、「エレクトロニクス・コンピューター」関連商品を購入した、という系列パターンであり、その信頼度・支持度・リフトは、それぞれ「0.38308」「0.090715」「0.976826」という意味になります。この状態でもアソシエーションルールの一部は見てとれますが、より分析をしやすくするためにTableauで可視化することにします。
次回は、作成したアソシエーションルールをBigQueryに書き出し、Tableauで可視化しながら、系列パターンの分析と、観察対象とするユーザーの抽出と行動観察を行います。


須川 敦史
UX&データスペシャリスト
クロスハック 代表 / uxmeetsdata.com 編集長
