
階層型クラスタリングを実践。
BigQueryにて分析データ環境が整ったところで、Cloud Datalabによるクラスター分析を行います。クラスター分析には階層型と非階層型の二つがあり、ここでは両方のアプローチを試みますが、今回は階層型クラスタリングを実践します。
階層型クラスタリング(Hierarchical Clustering)は、最も似ている対象の組み合わせから順にグルーピングしていく手法で、その過程で階層が構成され、最終的にデンドログラム(Dendrogram)と呼ばれる樹形図が完成します。順にグルーピングするため最初にクラスター数を決める必要はなく、後から決めることが可能であり、決めたクラスター数により最終的にどのグループをクラスターとするかが決まります。
まずはクラスターの分類構造を視覚的に捉えることが可能な階層型から行い、妥当なクラスター数のあたりをつけつつ、各クラスターの特徴を捉えてみることにします。
なお階層型クラスタリングではサンプル数が多いと極端に計算量が増え、また分類構造を捉えづらくなるためサンプリングデータで行います。分析対象データの会員数は64万人程度ですが、わかりやすさを重視して0.1%の636人にサンプリングします。前回作成した「sum_members_cls_smp」テーブルがそれに該当します。
まずはCloud Datalabで階層型クラスタリングのための実行環境を準備します。とはいえCloud Datalabには、GCP(Google Cloud Platform)との連携や、メジャーなデータ分析・機械学習系の拡張モジュールがあらかじめインストールされているため、インポートするだけです。データ操作やBigQueryとの連携用に「pandas」、作成したデントログラムの可視化用に「matplotlib」、各種計算処理用に「numpy」「scipy」 をそれぞれインポートします。
拡張モジュールの準備が完了したら、BigQueryで作成した分析用テーブルを取り込みます。それには「read_gbq」関数を使い、引数にBigQueryのクエリを実行するSQL文とGCPのプロジェクトIDを指定します。以下のコードを入力エリアに記述し、実行してみてください。
ウォード法による併合。
では、科学計算の拡張モジュールであるscipyを用いて、階層型クラスタリングを行います。以下のようなコードで実現できるので、入力エリアに記述し、実行してみてください。
なお、併合方法にウォード法を、測定距離にユークリッド距離をそれぞれ指定しています。ユークリッド距離(Euclidean Distance)については「クラスター分析入門 #01」で説明しているのでそちらを参照してください。ここではウォード法(Ward Method)について簡単に補足しておきます。クラスターXの重心とクラスター内の各要素との距離の二乗和をL(X)とするとして、クラスターAとBを併合したクラスターのL(A∪B)と、併合前のそれぞれのクラスターのL(A)およびL(B)の合計との差が最小になるようなクラスター同士を併合する手法がウォード法です。式で表現すると、以下のΔが最小になるように計算します。計算量は多いものの分類精度が高く、階層型クラスタリングの併合手法としてよく用いられます。
$$Δ = L(A∪B) -(L(A)+L(B))\\$$
実行結果として、以下のようなデンドログラム(Dendrogram)が描画されるかと思います。なお、上記のプログラムでthresholdという変数に8を指定していますが、これは縦軸の8の位置に水平方向の補助線を引くという意味で、その補助線とデンドログラムが交差する点がクラスターの分割ポイントとなります。すなわち指定する値によりクラスター数を変えることが可能ということです。冒頭で階層型は最初にクラスター数を決める必要はなく、後から決めることが可能だと言いましたが、これがそのことです。補助線で分割された各クラスターは色分けして描画され、左から順に正の整数でクラスターIDが付与されます。
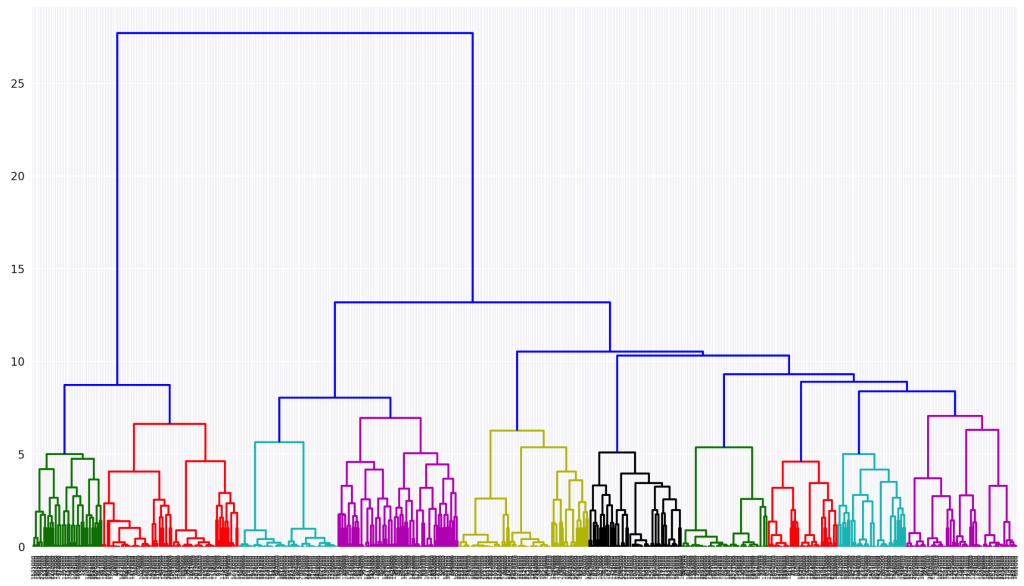
このデンドログラムから、クラスター数は10程度が妥当ではないかというあたりがつけられます。とはいえ各クラスターの特徴や、なぜこのように分類されたのかがわかりません。それにはクラスターごとに特徴量を見る必要があります。
Tableauで可視化するとわかりやすいので、クラスタリング結果をいったんBigQueryに戻します。以下のコードを入力エリアに記述し、実行してみましょう。なお「to_gbq」関数の引数には、元の会員マスタにクラスターIDである「cluster」列を追加したデータフレーム、書き込み先のテーブル名、GCPのプロジェクトIDを指定します。
なお、BigQueryへの書き出しがうまく行かない場合は、以下のコードでCSVファイルに書き出し、GCS(Google Cloud Storage)経由でBigQueryに取り込みます。
クラスターごとの特徴を可視化。
「sum_clusters_hrc」テーブルをTableauで可視化します。クラスターIDを[行]、各説明変数の平均を[列]シェルフにそれぞれ設定すると、以下のようなビューが表示されます。
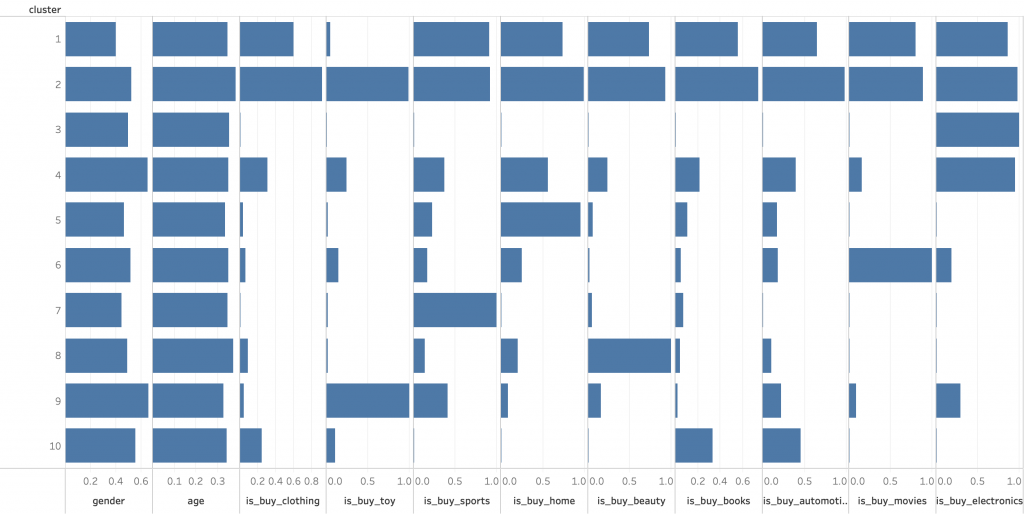
説明変数はすべて0から1の値であるため、平均値の範囲も同様になります。また、平均値が0から1のどこにあるかで変数の特徴がわかります。たとえばクラスターID:1は性別が0.4程度と男性の比率が高く、クラスターID:4は性別が0.6程度と女性の比率が高いことがわかります。
このようにクラスターごとの各変数の値を見ることで、各クラスターの特徴や、なぜそのように分類されたのかが見えてきます。具体的には、クラスターID:2は男女比率が同程度で、平均年齢は30代後半、全商品カテゴリを購入しているセグメント、クラスターID:4は女性の比率が高く、平均年齢は30代半ば、主に「エレクトロニクス・コンピューター」「家庭・ガーデニング用品」を購入しているセグメント、などがわかります。
また全体感として平均年齢にあまり差異はなく、分類にはほぼ影響していないことがわかります。性別については、男女比40%から60%の範囲でばらついており、やや影響していることがわかります。購買商品カテゴリについては、全商品カテゴリを購入している層と特定の商品カテゴリのみを購入している層に分かれていることがわかります。これは購入頻度との相関がありそうです。
ここでの階層型クラスタリングは、わかりやすさを重視してサンプル数をかなり減らしており、統計的な信頼度は低いといえます。しかしながら、仮説として妥当なクラスター数のあたりをつけたり、どのように分類されるかの傾向を見るには十分な材料と言えるでしょう。
次回は非階層型クラスタリングを実践します。


須川 敦史
UX&データスペシャリスト
クロスハック 代表 / uxmeetsdata.com 編集長
