
非階層型クラスタリングを実践。
前回は階層型クラスタリングでクラスター数のあたりをつけ、各クラスターの特徴を捉えました。今回は非階層型クラスタリングを実践します。
非階層型クラスタリング(Non-hierarchical Clustering)は階層的な構造を持たず、最初に決めたクラスター数にサンプルを分けていく手法です。ただし、いくつのクラスターに分けるかは分析者が決める必要があり、最適クラスター数を自動的には計算する方法は確立されていません。階層型と比較して計算量が少なく、サンプル数が多いデータの分析に適しています。
まずは階層型クラスタリングの結果との比較を行うため、前回と同様にサンプリングデータである「sum_members_cls_smp」を使用します。
まずはCloud Datalabで非階層型クラスタリングのための実行環境を準備します。とはいえCloud Datalabには、GCP(Google Cloud Platform)との連携や、メジャーなデータ分析・機械学習系の拡張モジュールがあらかじめインストールされているため、インポートするだけです。データ操作やBigQueryとの連携用に「pandas」、作成したクラスターの主成分分析の結果の可視化用に「matplotlib」、各種計算処理用に「numpy」「scikit-learn」 をそれぞれインポートします。
拡張モジュールの準備が完了したら、BigQueryで作成した分析用テーブルを取り込みます。それには「read_gbq」関数を使い、引数にBigQueryのクエリを実行するSQL文とGCPのプロジェクトIDを指定します。以下のコードを入力エリアに記述し、実行してみてください。
K平均法による併合。
では、機械学習用の拡張モジュールであるscikit-learnを用いて、非階層型クラスタリングを行います。以下のようなコードで実現できるので、入力エリアに記述し、実行してみてください。
なお、分類方法にはk平均法を用いています。k平均法(k-Means Method)は非階層型クラスタリングの代表的な分類手法で、クラスターの平均を用い、与えられたクラスター数k個に分類することからこのように命名されたものです。この計算処理にはscikit-learnのKMeansメソッドを用います。
また、k平均法の結果は多次元の距離で表現されるため、可視化するには次元圧縮を行う必要があります。次元圧縮のアルゴリズムとして最も一般的なのは主成分分析(Principal Component Analysis:PCA)ですが、ここでは非線形データを扱えるカーネル主成分分析(Kernel PCA)を選択します。この計算処理には同じくscikit-learnのKernel PCAメソッドを用います。結果をクラスターごとに色分けして散布図で描画すると以下のようになります。
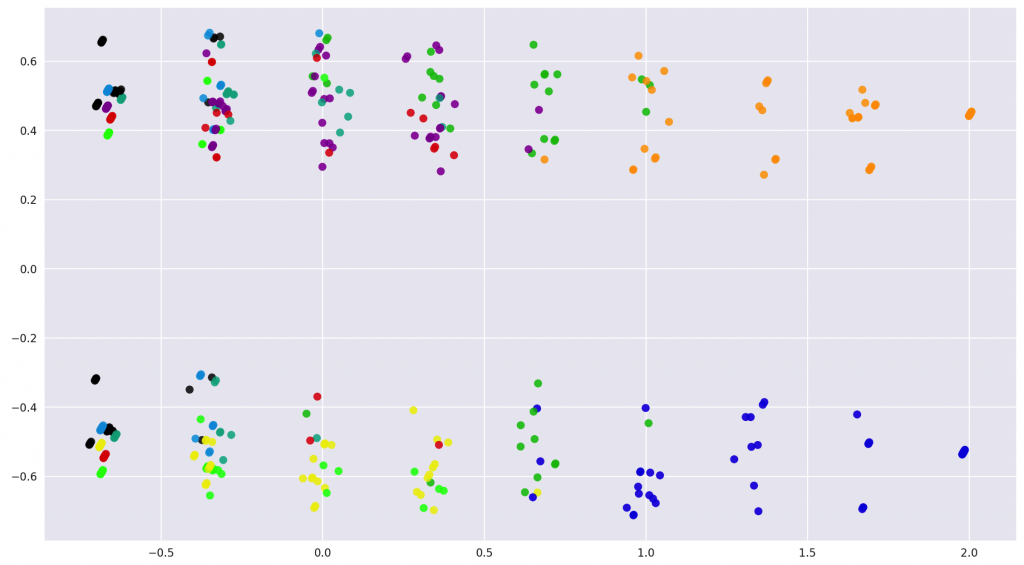
この散布図から、大きく上下に塊が分離していることがわかります。これは縦軸に性別が選択された結果です。年齢はクラスタリングに影響を与えておらず、無視されています。横軸には商品カテゴリの購買傾向が表現されており、右側のオレンジとブルーの塊は、全商品カテゴリを購入している層となります。このうように散布図を見ることで、ある程度は視覚的に捉えることができます。とはいえ詳しく把握するには、クラスターごとに特徴を見る必要があります。
Tableauで可視化するとわかりやすいので、クラスタリング結果をいったんBigQueryに戻します。以下のコードを入力エリアに記述し、実行してみましょう。なお「to_gbq」関数の引数には、元の会員マスタにクラスターIDである「cluster」列を追加したデータフレーム、書き込み先のテーブル名、GCPのプロジェクトIDを指定します。
なお、BigQueryへの書き出しがうまく行かない場合は、以下のコードでCSVファイルに書き出し、GCS(Google Cloud Storage)経由でBigQueryに取り込みます。
クラスターごとの特徴を可視化。
「sum_clusters_non」テーブルをTableauで可視化します。クラスターIDを[行]、各説明変数の平均を[列]シェルフにそれぞれ設定すると、以下のようなビューが表示されます。
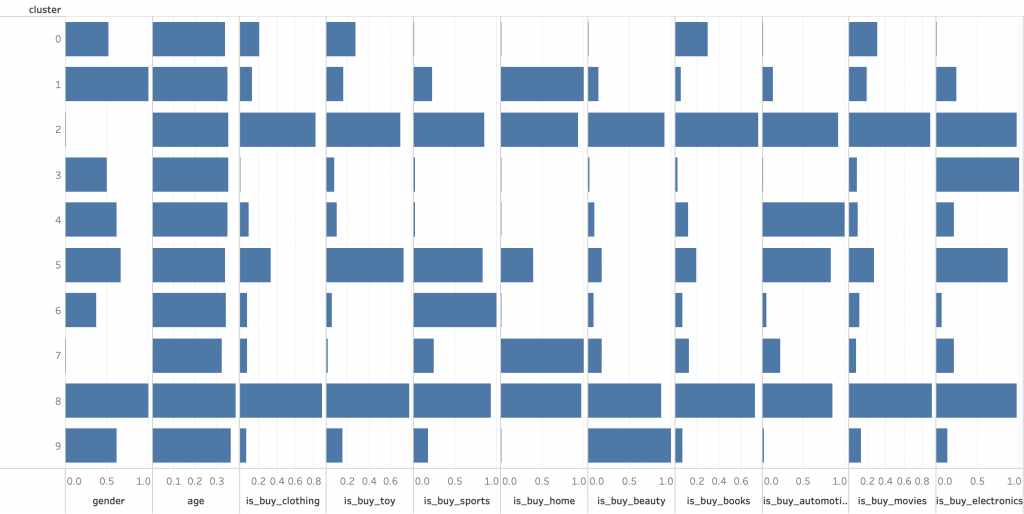
クラスターごとの特徴を見ると、クラスターID:1は女性のみで構成され、平均年齢は30代半ば、主に「家庭・ガーデニング用品」を購入しているセグメント、クラスターID:2は男性のみで構成され、平均年齢は30代半ば、全商品カテゴリを購入しているセグメント、などがわかります。
階層型と比較して、性別による分類が強く働いていることがわかります。また平均年齢については階層型と同様に分類にはほとんど影響を与えていません。購買商品カテゴリについては階層型と似たような分類結果となっています。
ここまでは階層型との比較のため、サンプリングデータを用いた非階層型クラスタリングを実施しましたが、同様の手順でノンサンプリングデータについても実施することが可能です。それには「sum_members_cls_non」テーブルを使用します。このデータの非階層型クラスタリングの分析結果も、上記と同様にTableauで可視化すると、以下のようなビューが表示されます。
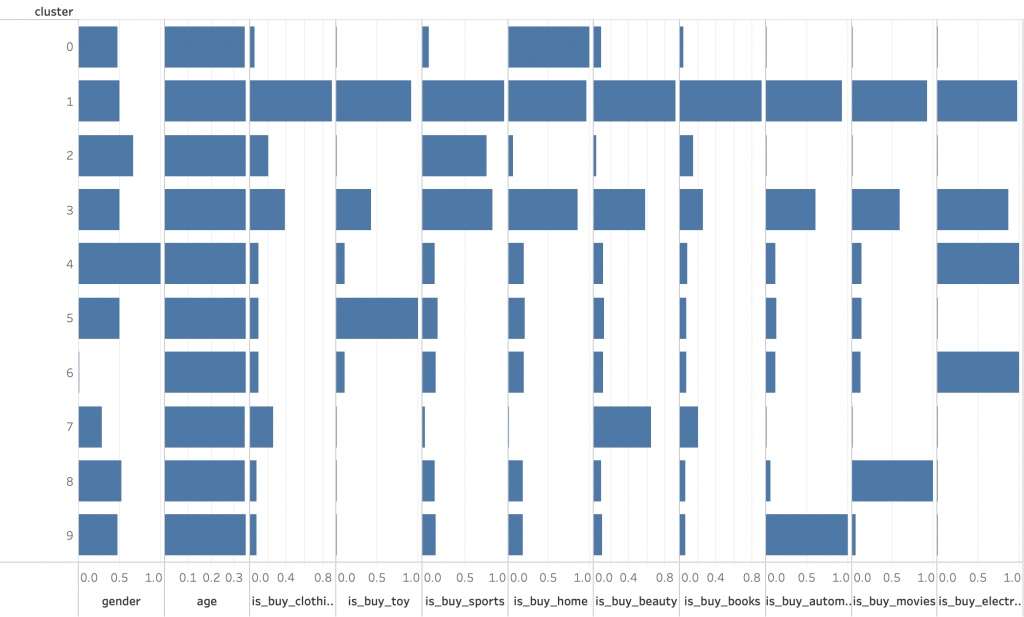
クラスターごとの特徴を見ると、さきほどは男女で分かれていた全商品カテゴリ購買層が統合されて一つのクラスターになっているなど、分類に対する性別の影響力が弱まっており、概ね商品カテゴリの購買傾向による分類になっていることがわかります。これはサンプル数が増えているにも関わらず、購買傾向のパターンが増えずに固定化されることで影響力が高まり、相対的に性別の影響力が低下しているものと思われます。購買商品カテゴリの変数の値を購買頻度に合わせて重み付けするなど行えば、また違った分類結果が導出される可能性があります。
ここまで階層型および非階層型の両方のアプローチによるクラスター分析の実践を進めてきましたが、今回のようなビッグデータでもサンプル数を減らすことで階層型クラスタリングを実行でき、分類構造を視覚的に捉えながら妥当なクラスター数にあたりをつけた上で、最終的に非階層型クラスタリングでノンサンプリングデータの分類が可能であることがわかったかと思います。
このプロセスにより、大量の顧客データから「似た者同士」であるセグメントを分析し、すべての顧客データに割り当てた上でパーソナライゼーションを実行することが可能となります。


須川 敦史
UX&データスペシャリスト
クロスハック 代表 / uxmeetsdata.com 編集長
