
Cloud Datalabでクラスター分析。
ここからクラスター分析の実践を進めて行きますが、分析ツールはGoogle BigQueryとGoogle Cloud Datalabを用います。BigQueryついては「BigQueryではじめるSQL」、Cloud Datalabについては選択する理由と合わせて「アソシエーション分析入門 #02」に詳しいのでそちらを参照してください。
なお、Cloud Datalabに近いものとして「ColabではじめるPython」でも紹介した、同じくGoogleが提供するGoogle Colab1)ColabではじめるPythonという無料サービスがあります。ただ、Colabはあくまで教育・研究用であり、秘匿性の高いデータを扱うことができないなどの制約があるため、ビジネス利用にはCloud Datalabを推奨します。
今回は「データエスノグラフィ入門」と連動し、とある総合ECサイトの会員のセグメンテーションを行うという設定でクラスター分析の実践を行うため、ビジネス利用を想定し、Cloud Datalabを用いることにします。
新しい商品カテゴリの提案。
それでは、Cloud Datalabを利用したPythonによるクラスター分析のプログラミングを実践していきます。まず分析の背景と目的を整理します。
あなたは、とある総合ECサイトの責任者です。ECサイトでは、F2転換率が重要であると言われています。この”F”は購買頻度(Frequency)のことで、F2転換率とは初回購買から二回目購買への転換率(Conversion Rate)を意味します。一般的に、新規会員の獲得よりも、既存会員のリピート購買促進のほうがコスト効率が高いため、F2転換率は重要な指標となります。とはいえF2転換した会員が、その後も継続的に購買してくれる、いわゆる優良会員になるとは限りません。
そこで今回の分析目的を「優良化する会員の行動特性を、購買履歴データから把握する」とします。なおそこには、まだ優良化していな会員を意図的に優良化するためのヒントがあることは言うまでもありません。
分析対象データは、とある総合ECサイトの会員の購買履歴データで、概要は以下のとおりです。
- 種類:総合ECサイトの会員の購買履歴
- 期間:2005年1月〜2013年12月(9年間)
- 会員数:639,777人
- 購買数:7,599,650件(平均11.9件/人)
データソースは以下の3つを使用します。なお、こちらはすでにBigQueryに投入済みとします。
| データソース | 変数 | ダウンロード |
| 会員マスタ mst_members |
会員ID, 年齢, 性別, 居住地など | [↓]105MB |
| 商品マスタ mst_products |
商品ID, 商品カテゴリなど | [↓]53MB |
| 購買履歴 trx_orders |
会員ID, 商品ID, 注文日, 価格 | [↓]698MB |
行動特性の分析を進める中で、購買商品カテゴリ数と優良化との間に相関があることがわかりました。(※「データエスノグラフィ入門 #04」を参照)これは、新たな商品カテゴリを提案することが優良化につながる可能性を示唆しています。ただし、闇雲に提案するよりも、類似する会員セグメントの併売傾向と照らし合わせ、未購買商品カテゴリを提案するほうが効果が高いと考えられます。そこでクラスター分析によりそれを明らかにします。
変数選択とダミー変数。
まずはクラスタリングに用いる説明変数を定義します。説明変数を定義することを変数選択や特徴選択といいますが、非常に難しい問題なので、ここでは深く触れず、ひとまず「性別・年齢・購買商品カテゴリ」とします。
次に、定義した説明変数の中で相関する変数がないかを確認します。「クラスター分析入門 #01」でも触れたとおり、クラスター分析において強い相関をもつ変数の存在は冗長で無意味であり、予めどちらかを除外する必要があります。
変数間の相関性は、質的変数であればクロス集計(Cross Tabulation)、量的変数であれば散布図(Scatter Plot)などの手法を用いて分析します。ここでは詳しいプロセスは省略しますが、各変数間に相関性が見られないことが下図にて確認できます。
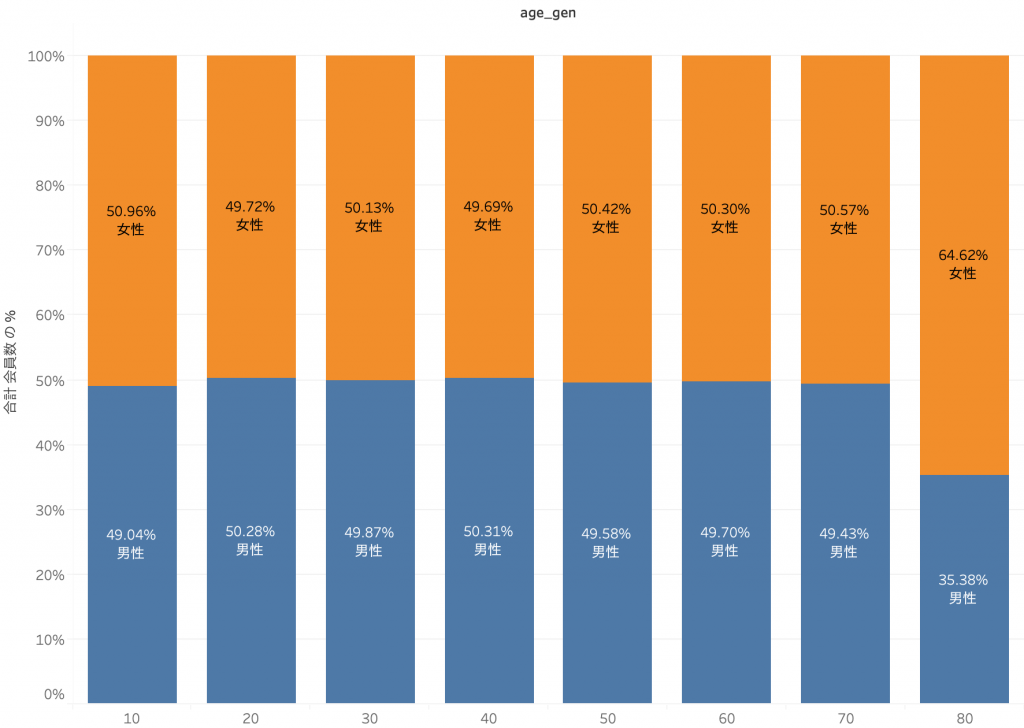
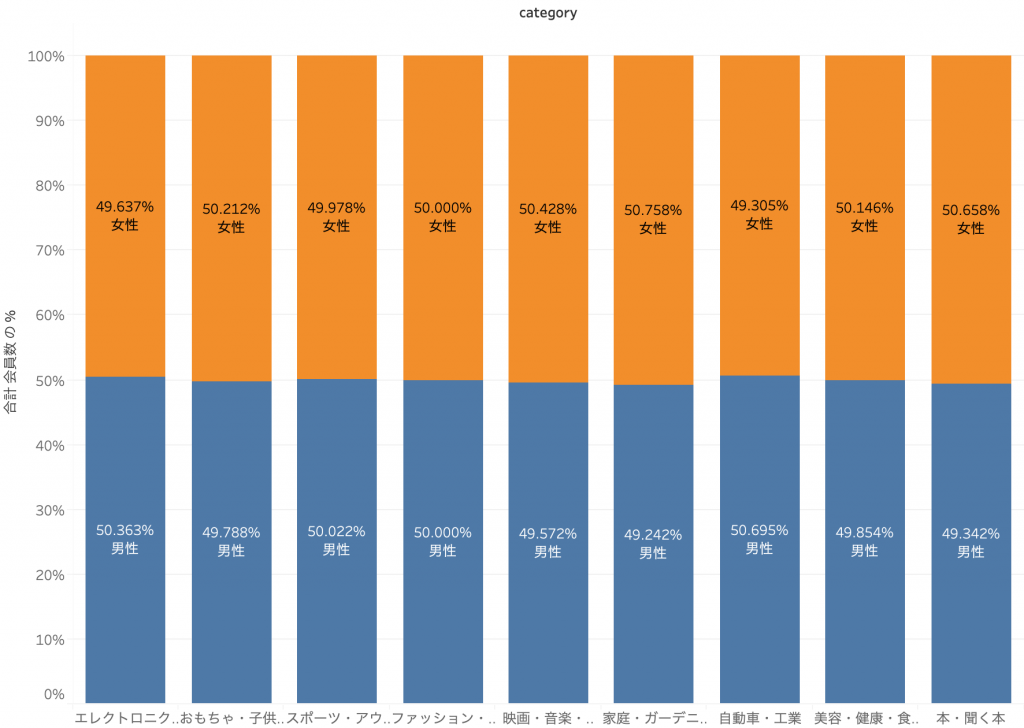
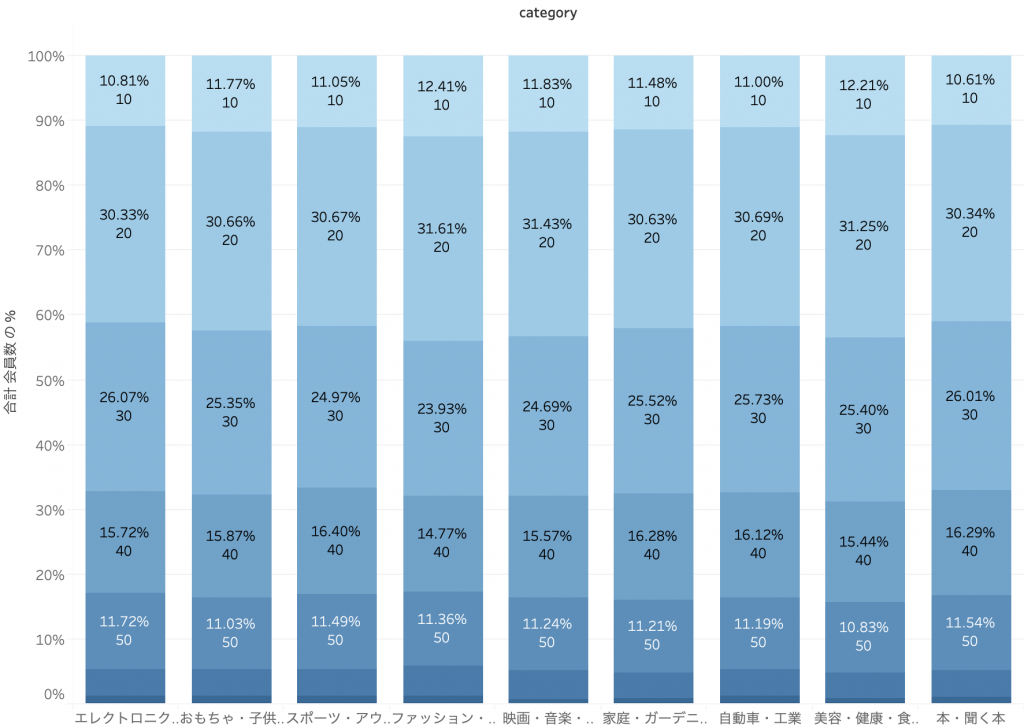
次にクラスタリング用のデータを用意するわけですが、ここでひとつ前処理が必要になります。「クラスター分析入門 #01」で説明したとおり要素間の距離を類似度とみなすことで類似性を分析するのですが、距離を測定するためには変数が数値化されている必要があります。年齢のような量的変数は問題ありませんが、性別や購買商品カテゴリは質的変数であるため、そのままでは数値として扱うことができません。そこでダミー変数という概念を用います。
ダミー変数(Dummy Variable)とは、質的変数を量的変数として扱うための変数のことで、0と1の二項値を持ちます。例えば、性別であれば”男性”と”女性”の二項値の場合はそのまま男性を0、女性を1のように設定します。
| 変数 | 値 |
| 性別(gender) | 男性:0、女性:1 |
ただし、最近では性別の選択肢に”その他”を設定しているケースも多く、その場合は二項値になりません。このような多項値の場合には、変数の値を別々の真偽値をもつ変数に分解し、偽を0、真を1のように設定します。
| 変数 | 値 |
| 性別が男性である(is_gender_male) | 偽:0、真:1 |
| 性別が女性である(is_gender_female) | 偽:0、真:1 |
| 性別がその他である(is_gender_other) | 偽:0、真:1 |
今回の対象データでいうと、性別は男性と女性の二項値になっているため、そのままダミー変数にすることができます。なお、購買商品カテゴリについては、それぞれについて購買経験の有無により真偽値を設定することとします。
ところで、年齢については量的変数であるため説明変数として扱うことが可能ですが、クラスタリングに使うには他の説明変数と値の範囲を揃える必要があります。すなわちダミー変数と同じ0から1の値になるように調整することになります。年齢はおよそ0歳から100歳なので、100で割った値を説明変数とします。なお、このように説明変数の値の範囲を変えることを特徴のスケール(Feature Scaling)、値の範囲を揃えることを正規化(Normalization)といいます。
以上を踏まえ、クラスタリング用のデータを以下のスキーマ定義で作成します。
| 変数 | 値 |
| 性別(gender) | 男性:0、女性:1 |
| 年齢(age) | 年齢の1/100 |
| 洋服の購買経験あり(is_buy_clothing) | 偽:0、真:1 |
| 玩具の購買経験あり(is_buy_toy) | 偽:0、真:1 |
| スポーツ用品の購買経験あり(is_buy_sports) | 偽:0、真:1 |
| 家庭用品の購買経験あり(is_buy_home) | 偽:0、真:1 |
| 美容用品の購買経験あり(is_buy_beauty) | 偽:0、真:1 |
| 本の購買経験あり(is_buy_books) | 偽:0、真:1 |
| 自動車用品の購買経験あり(is_buy_automotive) | 偽:0、真:1 |
| 映画の購買経験あり(is_buy_movie) | 偽:0、真:1 |
| 電化製品の購買経験あり(is_buy_electronics) | 偽:0、真:1 |
この定義に従ってBigQueryで分析用のテーブルを作成します。BigQueryのクエリエディタに以下のSQL文を入力し、青い[実行]ボタンをクリックしてみましょう。このクエリ結果をデータセット「DE」に「sum_members_cls_ non」という名前で保存します。なお、こちらはノンサンプリングデータになります。
また、計算量を減らし、かつ分類構造を視覚的に捉えやすくするため、ここでは主にサンプリングデータを用いることにします。クエリエディタに以下のSQL文を入力し、青い[実行]ボタンをクリックしてみましょう。このクエリ結果をデータセット「DE」に「sum_members_cls_smp」という名前で保存します。さきほどとの違いは、WHERE文に会員IDを1,000で割った剰余が0の場合に限定するという条件文を追加している点で[※1]、0.1%のサンプリングを意味します。
これで分析用のデータと環境は整いました。次回以降で、階層型・非階層型のそれぞれのアプローチでクラスター分析を進めて行きます。


須川 敦史
UX&データスペシャリスト
クロスハック 代表 / uxmeetsdata.com 編集長
脚注
| 1. | ↑ | ColabではじめるPython |
