ビッグデータ分析のためのSQL。
Google BigQuery1)BigQuery vs. Redshift どっち?は、Googleが提供するクラウドサービスで、フルマネージドなデータウェアハウス(Data Warehouse:DWH)であり、総合的なクラウドコンピューティングサービスであるGCP(Google Cloud Platform)の一部です。
BigQueryは、PostgreSQLなどの一般的なRDBでも使われている標準SQL(Standard SQL)で、大量データの処理に優れた列指向DB(Columner Database)でデータを自在に操作することが可能です。また、AWS(Amazon Web Services)のAmazon Redshiftとよく比較されますが、SQLの実行にブラウザUIを利用でき、さらに時間課金ではなくクエリ課金(クエリ時のデータスキャン量による従量課金)であるため、より手軽かつ安価にビッグデータのアドホック分析ができるという特徴を備えています。
そしてこのことは、これからビッグデータ分析のためのSQLを学びたい人のトレーニング用としても相性がよく、Googleのアカウントがあれば、いますぐSQLの練習を開始できます。
ではさっそく、BigQueryによるビッグデータ分析のためのSQLをはじめてみましょう。GCPコンソールにアクセスしてみてください。検索エンジンで「Google Cloud」と検索してもらっても結構です。すると、初めてアクセスする方にはチュートリアルが、ログイン経験がある方にはデフォルトプロジェクトのダッシュボードが表示されるかと思います。
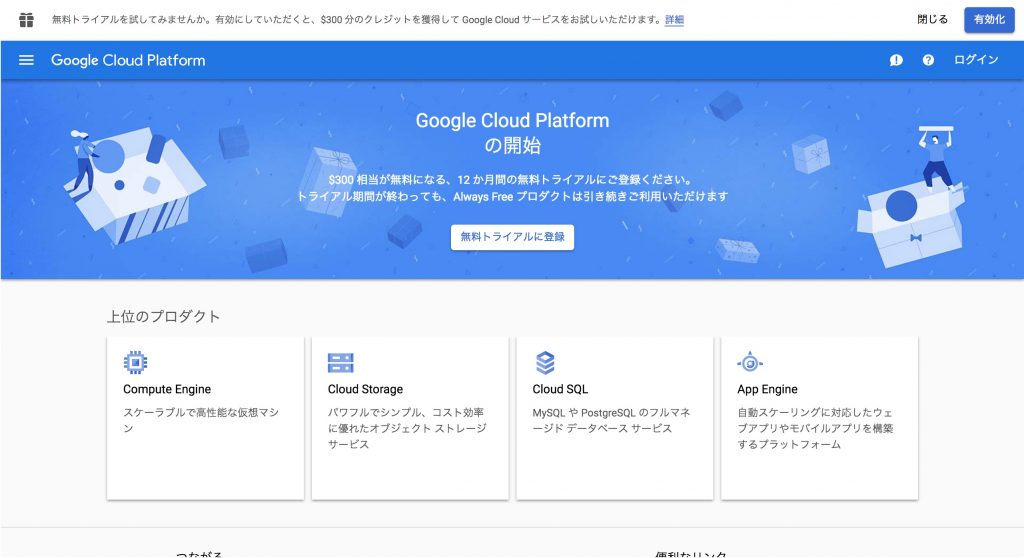
なお、GCPには12ヶ月間300ドル分の無料トライアルがあります。(2019年2月現在)画面上部[無料トライアルを試してみませんか…]の右横の[有効化]をクリックして、クレジットカードを登録すれば、無料トライアルを開始できます。また、無料トライアル終了後に自動的にクレジットカード課金されることはないので安心して利用できます。
ところで、GCPにはプロジェクト(Project)という特徴的な概念があります。BigQueryはもちろん、Cloud StorageやCompute EngineなどのGCPのすべてのサービスインスタンスがこれにひもづき、またプロジェクトごとに参加するアカウントを設定することができます。まさに、現実世界のプロジェクトの概念に近いものと言えるでしょう。仕事で使うには、まずはプロジェクトを作成するところからスタートしますが、練習用にはデフォルト設定されている「My First Project」で問題ありません。
Kaggleで練習用データを準備。
さて、GCPの準備が整ったところで、BigQueryによるビッグデータ分析のためのSQLに挑戦するわけですが、それには分析用データが必要です。手元にあるデータでもよいのですが、せっかくなのでビッグデータ分析に向いたデータで進めてみましょう。こんなときはKaggle(カグル)がおすすめです。
Kaggleは世界中のデータサイエンティストが集まるコミュニティーサイトで、最大の特徴はコンペの開催です。企業や政府がデータ分析や機械学習の課題を提示し、もっとも優れた分析や予測のモデルを賞金と引き換えに買い取る仕組みになっています。Kaggleに登録しているデータサイエンティストは、コンペへの参加や練習用データセットのダウンロードを無料で行えます。
ではKaggleに登録して、練習用データをダウンロードしてみましょう。Kaggleの登録はFacebookなどのSNSアカウントで簡単に行えます。登録が完了したら、ログインして「E-Commerce Data」というデータセットのページにアクセスしてみてください。こちらは、とあるECサイトの購買履歴データで、内容・サイズともにビッグデータ分析の練習用にはちょうどよいものとなっています。このページの右上部の「Download」というリンクをクリックすれば、練習用データの準備は完了です。
簡単なクエリにトライ。
練習用データをさっそくBigQueryで操作してみましょう、と行きたいところですが、もう少し準備が必要です。BigQueryでデータを操作するには、テーブル(Table)を作成する必要があります。テーブルの作成には、データファイルをそのままBigQueryにアップロードする方法もありますが、ファイルサイズに10MBの上限がかかるため、今回の練習用データ(45.6MB)では使えません。別の方法として、Googleドライブを経由する方法とGCPのGoogle Cloud Storage(GCS)を経由する方法がありますが、ここではGCSを経由する方法を選択します。
GCPコンソールの左上のハンバーガーメニューをクリックすると、GCPで利用できるサービスメニューが開くので[Storage]をクリックをしましょう。ここに練習用データをアップロードするわけですが、そのためにはバケット(Bucket)の作成が必要になります。バケットはフォルダのようなものと考えてください。画面上部の[バケットを作成]をクリックし、任意の名前をつけて作成します。あとはそのバケット内に入り、練習用データファイル「data.csv」を画面内にドラック&ドロップするか、[ファイルをアップロード]ボタンをクリックすることで、練習用データをアップロードできます。
GCSへのアップロードが完了したら、BigQueryのテーブルへの取り込みを行います。サービスメニューの[BigQuery]をクリックしましょう。ここでも、テーブルを作成する前にデータセット(Dataset)を作成する必要がありますが、こちらもフォルダのようなものになります。右下ペインにある[データセットを作成]をクリックし、任意の名前をつけてデータセットを作成します。ここでは「Training」と命名します。すると左ペインに作成したデータセット「Training」がツリー状で表示されるので、それを選択し、右下ペインにある[テーブルを作成]をクリックします。
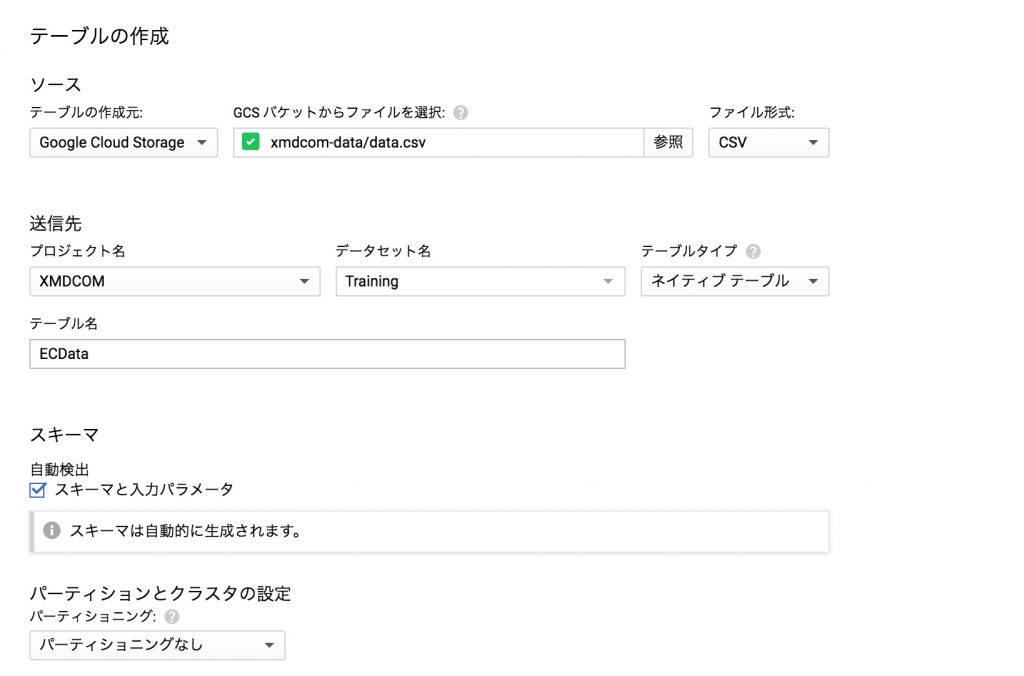
そこで表示される[テーブルの作成]画面で、GCSにアップしたデータを取り込んでテーブルを作成します。手順は以下のとおり。
- [テーブルの作成元]で[Google Cloud Storage]を選択
- [GCS バケットからファイルを選択]で「data.csv」を選択
- [ファイル形式]で[CSV]を選択
- [テーブル名]に任意のテーブル名を入力(ここでは「ECData」と命名)
- [スキーマと入力パラメータ]にチェック
- [詳細オプション]のアコーディオンを開く
- [スキップするヘッダー行]に「1」を入力
- [テーブルを作成]ボタンをクリック
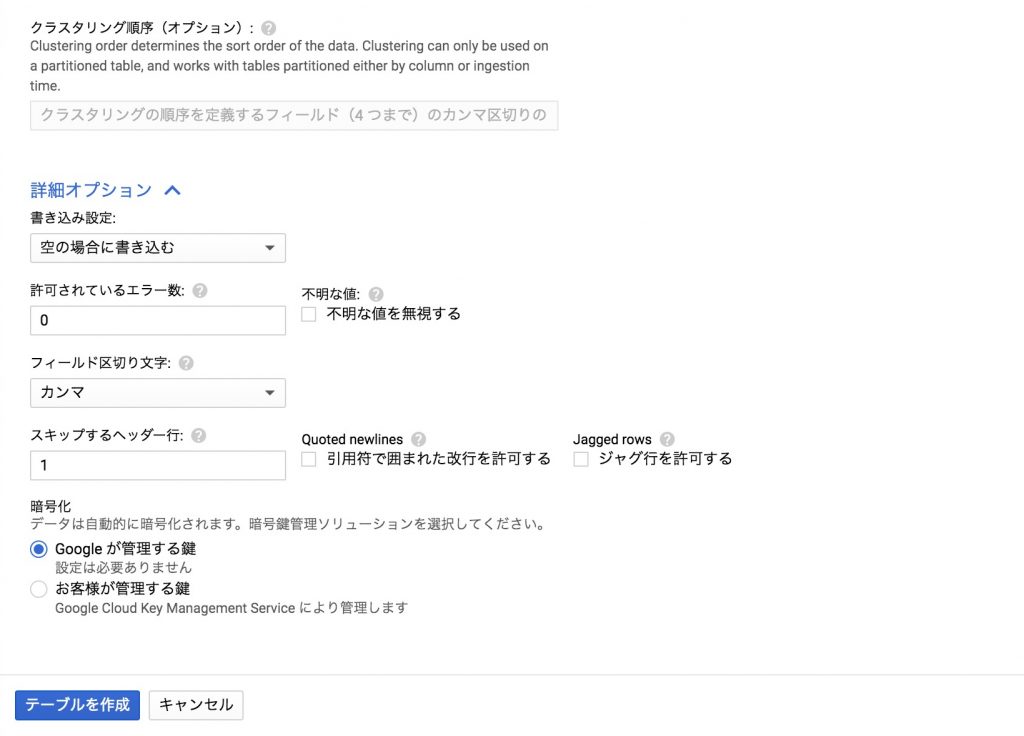
すると左ペインに作成したテーブル「ECData」がツリー状で表示されているかと思います。これでテーブルの作成は完了です。
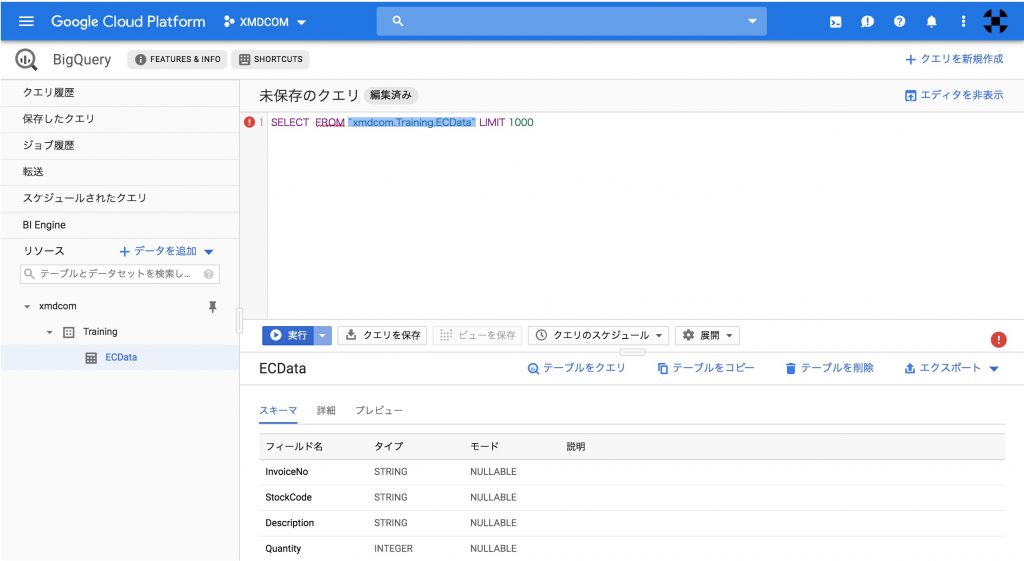
試しに、簡単なSQL文を実行してみましょう。左ペインで作成したテーブルをクリックすると、右下ペインにテーブルのデータが表示されます。その状態で、同じく右下ペインの[テーブルをクエリ]をクリックしてみてください。すると右上ペインに「SELECT FROM ‘Training.ECData’ LIMIT 1000」というSQL文が表示されるかと思います。そのSQL文の「SELECT」と「FROM」の間に「InvoiceNo, StockCode」というテキストを挿入して、青い[実行]ボタンをクリックしてみましょう。「InvoiceNo」と「StockCode」の二つの列と1,000行に絞られたデータが右下ペインに表示されるかと思います。このように非常に手軽にSQLを実行することができるわけです。
SELECT
InvoiceNo
,StockCode
FROM 'Training.ECData'
LIMIT 1000
では次回以降で、ビッグデータ分析のためのSQLの実践に踏み込んで行きたいと思います。

須川 敦史
UX&データスペシャリスト
クロスハック 代表 / uxmeetsdata.com 編集長
脚注
